The feature I mentioned in “SQL: joins and duplicates” is now implemented in Glom 1.3.3. It’s just a matter of choosing relationships from a tree rather than just a list, though it’s only 2 levels deep for now to keep it simple.
So if there are, for instance, Invoices with related Invoice Lines records, which refer to Products, then you could look at a Product details screen and see all the Invoices that use the Product (via their Invoice Lines records). If I added a 3rd level of child relationships then you could even see all the Customers (used by the Invoice table) that had ever been invoiced for the product.
Here’s a screenshot of the UI for the Licenses, Packages, Package Scans example:
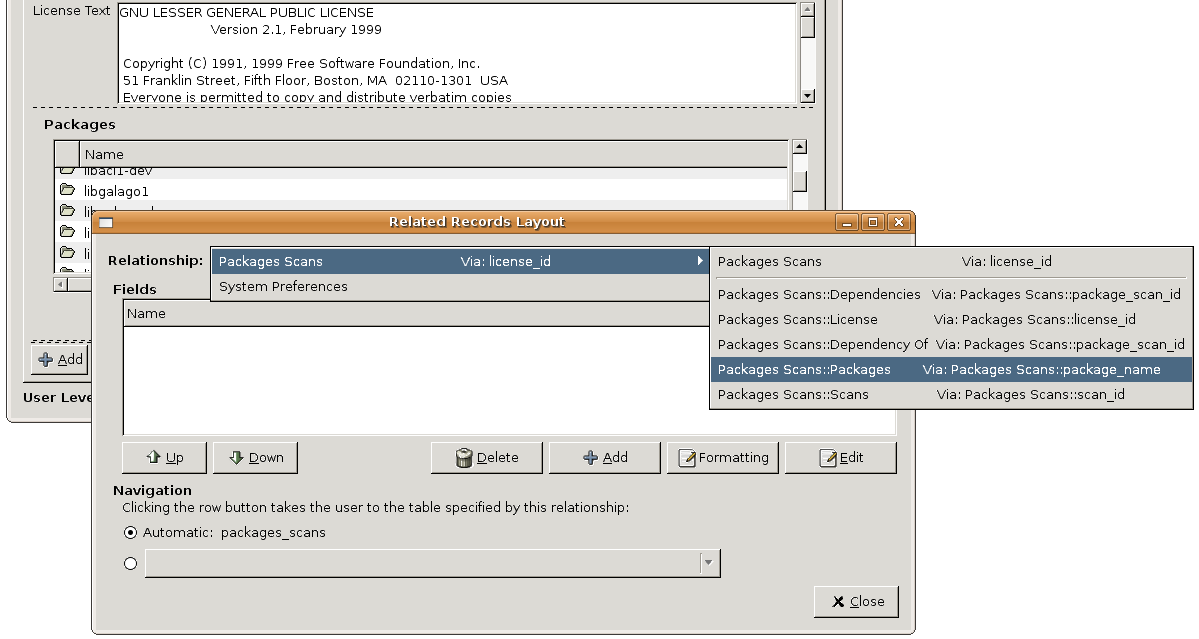
The UI isn’t perfect. I don’t like that it’s enabled via a checkbox but I think the tree would be confusing if it was default. Trees in GtkComboBox widgets are also rendered as these confusing menus, but it could be replaced by a popup GtkTreeView some day. But I feel very satisfied that I’ve made it easy to do something that’s usually difficult, with only minor UI changes. Many thanks to Jerry Haltom for showing me how this could be done.
The SQL that’s generated is much the same as for regular related records (SELECT related_table.field1, related_table.field2 FROM related_table WHERE related_table_field3 = 123), but with an extra JOIN … AS … ON clause to link to the intermediate table, a slightly changed WHERE clause (to refer to that intermediate join), and a GROUP BY on the related table’s primary key to ensure that we get only one row for each related record. A sub-select query might be more efficient, but this allows me to reuse the existing code, and lets the user think in terms of the target related table rather than an intermediate one.
So using Glom’s –debug_sql now shows yet more complex SQL that you wouldn’t want to write yourself.
“A sub-select query might be more efficient, but this allows me to reuse the existing code”
Ouch! Somewhere in the world, a DBA just lost its wings.
Feel free to turn on –debug_sql and suggest more efficient versions of the SQL statements, or even patch the function that generates it.
You can achieve SQL code re-use by all kind of measures, e.g. database views or user-defined functions or stored procedures or some logic that assembles SQL on-the-fly (of course avoiding SQL injection).
I can only recommend to avoid “group-by” and/or “distinct” for the cause of removing unwanted duplicate rows produced by inaccurate joins. Not only because of performance reasons, but also because this approach might also turn out to be semantically incorrect. Duplicate result rows may as well occur because of data equality, and then you most likely do not want to throw them away, etc.
> Duplicate result rows may as well occur because of data equality, and then you most likely do not want to throw them away, etc.
Yes, that’s why I only group on the primary key (which I always get for internal use, though it’s not always shown.)
Sorry, it took me awhile to finally get back to a linux box, but I’m trying now. It looks like it’s not accepting the -debug_sql parameter though. Do I need to roll my own glom or should a prepackaged one work? I’m using 1.3.5 on Ubuntu.
mikey@belldandy:~$ glom -debug_sql
Exception: Unknown option -debug_sql
terminate called after throwing an instance of ‘Glib::OptionError’
Aborted (core dumped)
Mikey, yes, I get that error too with the Ubuntu-packaged version, though it works for my locally-built one. Could you file a bug in Ubuntu’s launchpad, please?
Figured it out. Looks like when it was packaged for Ubuntu, the command was changed to a double-dash (–debug_sql). The man page also shows -h as being the help command, though it appears to have been changed to -? in the executable. I’ll file a bug in launchpad.
Mikey, did you ever look at this? I’d still welcome any suggestion to improve the SQL for this.